/ Cluster · Similar YouTube channel finder
Similar YouTube channel finder: format-fingerprint similarity, not audience overlap
A similar YouTube channel finder is doing one of four jobs depending on which "similar" the searcher means: audience-overlap similarity, topic-keyword similarity, recommender-graph similarity, or format-fingerprint similarity. The first three are the slices vidIQ Suggested Channels, Social Blade, and YouTube's own "Channels related to" sidebar serve. The fourth — finding small channels currently breaking out that share the format-fingerprint of a reference channel — is the slice that matters most for research and modeling, and the slice NicheBreakout's library is built around. Public YouTube Data API v3 metadata only. Built from thousands of channels scanned to date.
The Friday digest reveals three current breakout channels every week for free, each one with a readable format fingerprint that pairs cleanly with similar-channel research. The live 30-day window — 319 channels under 30 days old right now — is the paid workflow surface; the matured public archive opens as a second free surface in summer 2026 once the first cohort ages out of the live window.
Open the live library →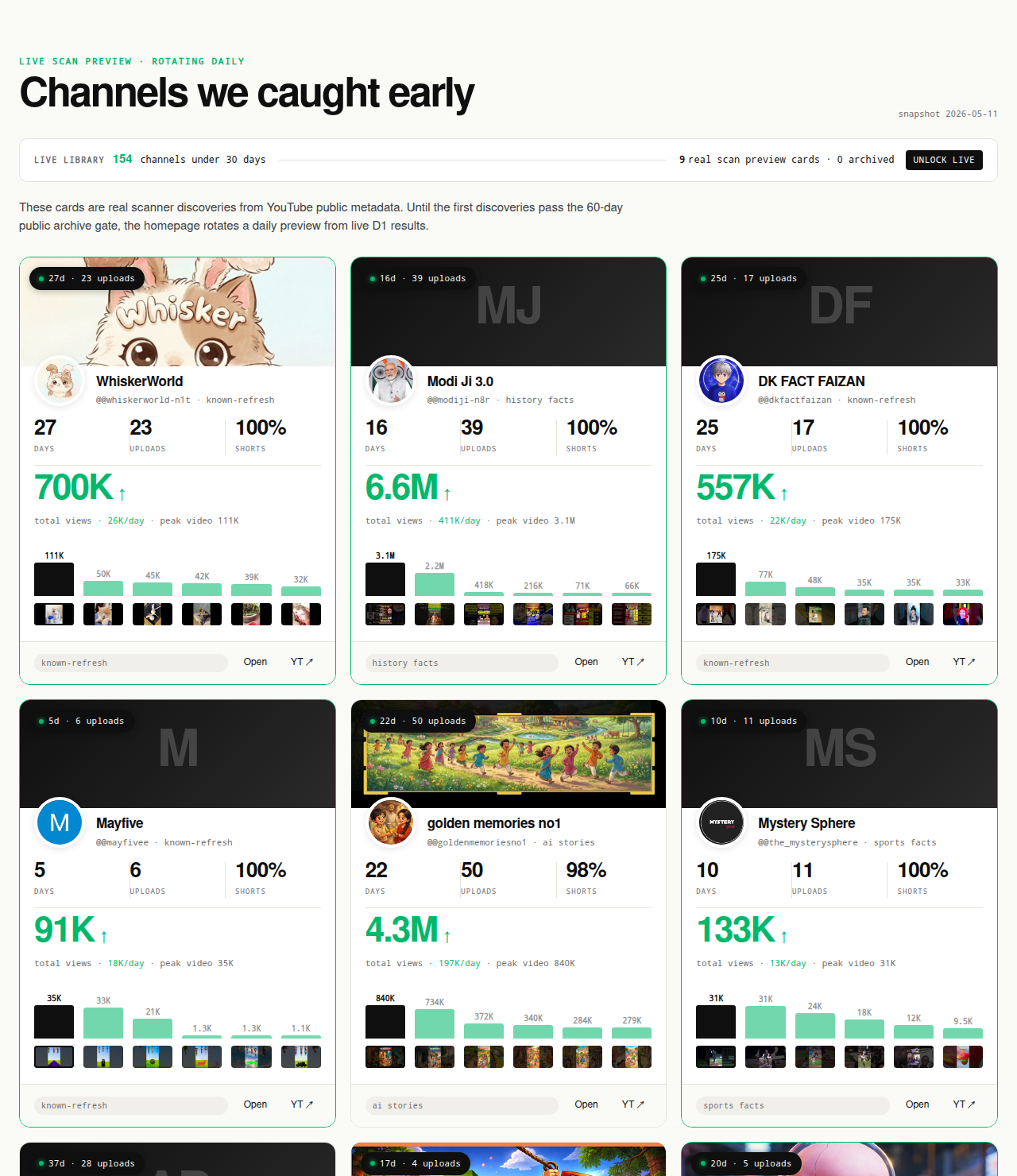
What "similar YouTube channel finder" actually means
The word "similar" is doing a lot of work in the head term. A searcher typing "similar YouTube channel finder" into Google in 2026 can mean any of four different definitions of channel similarity, and the SERP currently mixes all of them together. Audience-overlap similarity asks "which channels share viewers with the input channel," which is the model behind vidIQ's Suggested Channels view, Social Blade's similar-channel page, and most of the influencer-analytics tools that surface similar accounts for brand-deal vetting. Topic-keyword similarity asks "which channels use similar language in titles, descriptions, and tags," which is the model behind autocomplete-driven similar-channel tools and ChannelCrawler's filterable directory. Recommender-graph similarity asks "which channels does YouTube's own algorithm group with this one," which is the model behind YouTube's deprecated "Channels related to" sidebar and the third-party tools that scrape what's left of it. Format-fingerprint similarity asks "which channels publish the same format at the same recommender-readable cadence," which is the model this page argues matters most for research.
The four models do not produce the same outputs. A history-shorts channel publishing 90-second vertical TTS videos with cinematic stock footage every day can be audience-overlap-similar to a 2-million-subscriber face-on-camera history long-form channel — both serve viewers who like history content — while being format-fingerprint-dissimilar in every measurable way. A creator researching what to publish would learn nothing useful from the audience-overlap match. A creator pulling lists for advertising targeting would learn nothing useful from the format-fingerprint match. The choice of similarity model is the choice of which research question the tool is actually answering.
The honest read is that two channels can publish history shorts in the same niche but be wildly different from the recommender's perspective if their format-clarity, upload cadence, or thumbnail consistency differ. Recommenders read format consistency as a signal of which audience profile to map the channel to; a channel publishing daily 60-second history shorts at 9am UTC with the same thumbnail template trains the recommender on a clean profile, and a channel publishing irregular history content with mixed lengths and shifting thumbnail styles trains the recommender on a noisy profile. From the recommender's perspective those two channels are different products, even if a keyword-similarity tool groups them together. The argument this page makes is that similarity for research purposes means matching the format and publishing at recommender-readable cadence, not sharing keywords.
The rest of this page covers how the existing similar-channel tools work, why topic similarity beats audience similarity for new-channel research and format similarity beats both, the deterministic filter for finding similar small breakout channels, what NicheBreakout deliberately does not claim about similarity, and which clusters are currently surfacing format-similar small channels in our scans.
How existing similar-channel tools work, in one line each
Five surfaces currently fill the "similar YouTube channel finder" SERP, and each one operates on a different definition of similarity. The honest one-line read on each:
- vidIQ Suggested Channels — audience-overlap similarity weighted by recommender history. Strong on established channels with enough viewing history to surface co-viewing patterns; weak on channels under a few months old where the co-viewing graph is still sparse (vidIQ).
- Social Blade similar-channel lookups — overlap with vidIQ on the audience-similarity side, plus historical scraping context that lets the user compare growth curves across the similar set. Same public-data ceiling as the rest of the inspection tools.
- YouTube's own "Channels related to" sidebar — recommender-graph similarity surfaced directly by YouTube. The surface has been deprecated as a primary ranking signal and is missing from many channel pages; where it appears, it is the most direct read on the recommender's own associations.
- Autocomplete-driven similar-channel tools — topic-keyword similarity inferred from public titles, descriptions, and tags. Useful for surfacing channels using the same vocabulary as a reference; misses channels whose metadata uses different language for the same format.
- Recommendation-API-driven tools (ChannelCrawler-style) — filterable directories that approximate similarity through category, language, and subscriber-range filters. Closer to "channels in the same broad category" than "channels similar to this specific channel," but useful as a coarse prefilter.
None of these tools serve format-fingerprint similarity for small channels currently breaking out, which is the wedge NicheBreakout's library occupies. The five surfaces above are not broken — they answer the questions they were built to answer well. They are the wrong tool for the format-similarity-on-small-channels slice because that slice was not their design target. The right framing for a researcher running similar-channel queries is to pick the surface whose similarity model matches the actual research question, and to use multiple surfaces when the question spans multiple models.
Why topic similarity beats audience similarity for new-channel research, and format similarity beats both
For a researcher who already has an audience and is looking for adjacent channels their existing viewers might also watch, audience-overlap similarity is the right model. That is the influencer-marketing and brand-deal use case the major similar-channel tools were built around. For a creator with no existing audience yet — the most common situation for anyone running a "similar YouTube channel finder" query in research mode — audience-overlap similarity is the wrong model, because the creator does not have an audience yet for an overlap function to compare against. The relevant question is not "who shares my audience" but "what working channels should I be modeling."
Topic similarity is an improvement on audience overlap for that question. Knowing that a reference channel covers the same topic cluster as a candidate similar channel tells the researcher that the audience exists and is being served by at least one comparable operator. The problem is that topic alone underspecifies the channel. Two history channels can have wildly different production modes, video lengths, publish cadences, and thumbnail styles — and the recommender treats those differences as more important than the shared topic. A history-shorts channel and a face-on-camera history long-form channel are topic-similar, format-dissimilar, and end up serving different audience profiles in the recommender's index even though they share the surface topic.
Format similarity captures what topic similarity misses. The format fingerprint — video length distribution, Shorts ratio, faceless vs face-on-camera, thumbnail template consistency, upload cadence — is the variable the recommender reads most strongly when classifying a new channel into an audience profile. Two channels with the same format and different topics often serve more similar audiences than two channels with the same topic and different formats, because the recommender's "what to recommend next" decision tree is gated on format-fit signals first and topic signals second. A creator modeling a new channel learns more from a format-similar reference than from a topic-similar one, and learns the most from a reference that is similar on both axes.
The order that produces the best research output is: pick the format first, pick the topic cluster inside that format second, then look at small channels currently breaking out at that format-topic intersection as the similar-channel set to model. The reference channel functions as a fingerprint definition, not as the target to copy directly. The corollary is that the most useful similar channels for research purposes are usually small channels currently winning — they are inside the format-fit window where the format itself is being validated by the recommender, and the modeling lesson is about format-fit rather than about scaling effects that only show up at higher subscriber counts. The YouTube channel research parent pillar covers the broader discovery-plus-inspection workflow this argument sits inside.
The deterministic framework for finding similar small breakout channels
Format-fingerprint similarity needs a deterministic filter to be useful at scale. NicheBreakout applies three hard public-metadata gates to every candidate, then ranks the survivors with a deterministic score that weights two additional signals. The full methodology lives on the methodology page; the abbreviated version below is the signal list a researcher can apply with the public YouTube Data API directly when running a similar-channel query against a reference.
Channel age
detected within 45 days of channel creationFirst-5 upload views
combined views across the first five public uploads ≥ 10,000Views per day
lifetime channel views ÷ channel age ≥ 1,000Format clarity (bonus)
score weights channels with a clear Shorts-first or long-form-first ratio above mixed-format channelsEarly-traction velocity (bonus)
score boost when channel age ≤ 14 days, first-5 sum ≥ 50,000, or views/day ≥ 5,000
Each of the three hard gates isolates a different piece of the early-traction picture, and each one matters specifically for similarity-finding. Channel age ≤ 45 days filters to the cohort where format-fit signal is readable without subscriber inertia confounding the match; channels older than 45 days have had time for the recommender to override format signals with viewing-history signals, which makes them less useful as fingerprint matches. First-five-video sum views ≥ 10,000 filters out channels whose format-fit hypothesis has not yet been validated by the recommender; a five-upload sum below 10,000 means either the format is not working or the recommender has not yet classified the channel cleanly, neither of which produces a useful similarity signal. Lifetime views per day ≥ 1,000 is the cleanest velocity check available from public metadata alone and confirms the recommender is actively distributing the channel.
The two score bonuses sharpen ranking inside the filtered set in ways that matter for similarity-finding. Format clarity rewards channels with a consistent Shorts-first or long-form-first ratio, which is exactly the property that makes a channel useful as a similarity match — a format-mixed channel produces a noisy fingerprint that does not align cleanly with any reference. Early-traction velocity (channel age ≤ 14 days, first-5 sum ≥ 50,000, or views/day ≥ 5,000) pushes the freshest, fastest-moving channels to the top of the ranking inside any niche, which is where the format-fit signal is loudest.
Average first-five-video views for every populated grade tier inside our discoveries cohort looks like this (grades with no current members are suppressed until they fill in):
- 432,083 average first-5 views
The exact score formula and grade thresholds live on the methodology page. The cross-pillar how to find small YouTube channels guide walks through how to apply these signals manually without using NicheBreakout's library.
How to use NicheBreakout's library to find format-cluster siblings
The library is structured around the format-fingerprint similarity model. Every channel in the live library and the future matured archive carries the same fingerprint fields, so a similar-channel research workflow can run against either surface by reading the reference channel's fingerprint first and then filtering the library to matching values.
Today the free surface for similar-channel research is the Friday digest — three current breakout channels every week with their format fingerprints (Shorts vs long-form ratio, video length median, upload cadence, faceless vs face-on-camera label, topic cluster) and outbound YouTube links. The paid live library holds 319 channels currently inside the 30-day window with daily-refreshed traction signals. As the first cohort matures past the 60-day post-detection mark in summer 2026, the matured public archive will open as a second free surface alongside the Friday digest.
The practical workflow has four steps. Step 1. Open the reference channel on YouTube and read off its format fingerprint by hand: video length median (under 60 seconds, 60-180 seconds, 3-10 minutes, 10+ minutes), Shorts ratio (Shorts-first if more than 75% of uploads are vertical under 60 seconds), faceless or face-on-camera, thumbnail template consistency (locked template, evolving template, mixed), and approximate upload cadence (daily, several times a week, weekly, irregular). Step 2. Identify which programmatic topic page covers the reference channel's topic cluster — AI story channels, Reddit story channels, history shorts channels, faceless storytelling channels, quiz channels, or the broader live library if the topic does not fit a dedicated page. Step 3. Filter the topic page or library view to the matching fingerprint values from step 1. Step 4. Audit each candidate similar channel by clicking through to YouTube and confirming the fingerprint match against the reference.
The outbound-link audit in step 4 is the key trust mechanism. A similar-channel tool whose claims cannot be verified by clicking through to public YouTube pages is asking the reader to trust the operator's similarity model instead of the public data. NicheBreakout's design constraint is that the public data does the trust-building. Every channel card on every surface outbound-links to YouTube so the format-fingerprint match can be confirmed in one click. Filters, sorts, save-to-shortlist, and CSV export sit on the paid side of the line; browsing the matured archive and reading the Friday digest sit on the free side. See pricing for the current tier.
What we deliberately don't claim about similarity
NicheBreakout does not claim access to audience-overlap data for any channel a researcher does not own. The YouTube Analytics API restricts traffic-source breakdown, subscriber demographics, geographic distribution, and audience-affinity signals to authenticated channel owners; none of those fields are publicly readable, and no third party — including NicheBreakout — has access to them for channels they do not own (YouTube Data API: channels.list). The similarity model on this page is format-fingerprint similarity computed from public Data API fields, not audience-overlap similarity computed from private analytics. Any third party selling "audience overlap between channel A and channel B" for channels they do not own is either inferring from non-API sources (panel data, browser-extension tracking), extrapolating with assumptions the researcher cannot audit, or fabricating the number.
The product also does not claim recommender-graph access. YouTube's "Channels related to" sidebar — the closest public surface to the recommender's own similarity model — is deprecated, partial, and not exposed as a Data API endpoint. NicheBreakout does not scrape that sidebar, does not infer recommender associations from co-occurrence patterns, and does not report similarity scores that imply private recommender data. The similarity claims on this page are derived from public format-fingerprint fields and are auditable by clicking through to YouTube.
What is publishable from public Data API v3 fields for any channel and used in the format-fingerprint similarity model: channel age, video count, per-video duration distribution, per-video publish dates (which yield upload cadence), per-video view counts, video category IDs, channel description, channel banner, channel thumbnail. From those fields the format fingerprint is fully computable. From those fields audience overlap is not computable, traffic sources are not computable, and recommender-graph associations are not computable. The boundary is structural, not defensive — public-data-only is what makes every similarity claim verifiable on YouTube.
Common mistakes when searching for similar YouTube channels
Five mistakes recur when researchers run similar-channel queries. Copying the biggest channel in a cluster. The largest channel inside a format-topic intersection is downstream of years of recommender-trained audience momentum; its current strategy is the steady-state behavior of an already-trained channel, not the format-fit hypothesis a new entrant should model. The corrective is to model small channels currently breaking out inside the same cluster, which are the channels inside the format-fit validation window.
Treating subscriber count as the similarity proxy. Two channels with the same subscriber count can be wildly dissimilar in format and topic; two channels with very different subscriber counts can be highly similar in format and topic. Subscriber count tracks accumulated audience, not current similarity, and is rounded down to three significant figures by the Data API on top of being hide-able by the channel owner. The corrective is to read format-fingerprint fields directly rather than using subscriber count as a similarity shortcut.
Ignoring format-clarity in the similarity match. A format-mixed channel — three Shorts, one long-form, one livestream per week — produces a noisy fingerprint that does not align cleanly with any reference. Treating a format-mixed channel as similar to a clean Shorts-first reference channel produces a misleading research output. The corrective is to filter the similar-channel set to format-clear channels first, then run the topic-similarity match inside that filtered set.
Reading similarity from keywords alone. Two channels using the word "history" in their titles can be format-dissimilar enough that the recommender treats them as different products. A keyword-similarity match that does not also confirm format-fingerprint match overestimates the usefulness of the similar set for research. The corrective is to use keyword similarity as a coarse prefilter and format-fingerprint similarity as the ranking signal inside that prefilter.
Using a single similar-channel surface for every similarity question. The four similarity models cover different research questions; relying on one surface forces every question through one model. A researcher running similar-channel queries should match the surface to the question: vidIQ Suggested Channels for audience-overlap on established channels, ChannelCrawler for topic-keyword prefiltering across all sizes, YouTube's own sidebar where it still appears for recommender-graph reads, and NicheBreakout for format-fingerprint matches on small channels currently breaking out.
Each of these mistakes shares a root cause: the researcher is using a similarity definition that does not match the research question. The discipline change is to name the question first — audience-overlap, topic-keyword, recommender-graph, or format-fingerprint — and pick the surface accordingly. The sibling YouTube channel finder cluster page covers the broader channel-finder category that this similar-channel slice sits inside.
The clusters where format-similar small channels are currently breaking out
The similar-channel output is most useful when it points at specific format clusters where the small-channel-breakout signal is firing right now, because those clusters are where a researcher can find multiple format-similar small channels to triangulate against a single reference. Across the 319 channels currently in our live 30-day window (a subset of the broader thousands of-channel scan), the densest format clusters currently meeting our sample-size threshold are:
- 38.4 hotness score
- 36.8 hotness score
- 35.9 hotness score
This is what we have observed in our scans, not a market-wide claim, and it shifts week over week as new format clusters surface and older ones saturate. Read it as a current snapshot. The Shorts-first vs long-form split inside those top clusters looks like this in our dataset:
The clusters surfacing the most format-similar small channels are usually faceless or Shorts-first formats — AI storytelling, history shorts, Reddit narration, quiz/trivia, faceless storytelling — because those formats have the lowest production cost per upload, which lets a single operator publish enough times inside the 45-day early-traction window to produce a readable fingerprint. Face-on-camera long-form channels also produce format-similar clusters but at lower density.
Five recurring clusters have dedicated programmatic topic pages where each cluster's currently-breaking-out format-similar channels are indexed with the same outbound-link verification as the main library:
- AI story channels: TTS narration plus AI imagery, recurring story templates, Shorts-first publishing.
- Reddit story channels: TTS reading r/AmITheAsshole, r/ProRevenge, r/MaliciousCompliance threads with stock visuals or simple character overlay.
- History shorts channels: fact-stacking with cinematic visuals, vertical and horizontal variants.
- Faceless storytelling channels: broader narrative format spanning fiction and non-fiction.
- Quiz channels: interactive Q&A format, often Shorts-first with text overlays.
If you are using this page as a similar-channel finder entry point, the programmatic pages above are the natural next click: each is a pre-filtered candidate cohort for a format-fingerprint similarity workflow to run against. The faceless YouTube niches and YouTube Shorts trends sister pillars cover the production-mode and surface-mode angles for the operators picking which cluster to use as a similarity reference first.
FAQ
How do I find channels similar to a specific YouTube channel?
Start with the channel's own "Channels" tab on YouTube, which still surfaces a small set of related channels for some pages, then run the channel's @handle through vidIQ's Suggested Channels view or Social Blade's similar-channel lookup for a broader list. Both wrap signals derived from co-viewing patterns and metadata overlap. For finding small channels currently breaking out at the same format-topic intersection as your reference channel — a different question than the one those tools answer well — read the reference channel's format fingerprint (video length, faceless vs face-on-camera, Shorts ratio, thumbnail style, upload cadence) and use NicheBreakout's library or the topic-specific pages linked on this page to surface small channels matching that fingerprint.
What's the best similar-YouTube-channel tool?
It depends on whether you want audience-overlap similarity, topic-keyword similarity, or format-fingerprint similarity. vidIQ's Suggested Channels view is the most-used surface for audience-overlap similarity for established channels. Social Blade's similar-channel page and tubebuddy's adjacent surfaces serve a similar slice. ChannelCrawler is closer to topic-keyword similarity through its filterable directory. None of those tools pre-filter for small channels currently breaking out, which is the slice NicheBreakout serves. A single tool that does all three well does not currently exist; most operators end up using one for the broad similarity question and one for the small-channel slice.
Can I see what channels YouTube recommends for a specific channel?
Partially, and decreasingly. YouTube's own "Channels related to" sidebar still appears on some channel pages and surfaces channels the recommender associates with the input channel based on co-viewing behavior. The surface has been deprecated as a ranking signal and is missing from many newer channel pages. The YouTube Data API does not expose a public "related channels" endpoint — the closest available field is per-channel relatedPlaylists, which references playlists, not channels. Third-party tools that claim to show "channels YouTube recommends" are usually scraping the visible sidebar where it still appears, or inferring associations from co-occurrence in playlists and video descriptions. Treat their output as adjacent to YouTube's own signal, not as direct access to it.
How does NicheBreakout differ from vidIQ Suggested Channels?
vidIQ's Suggested Channels view answers "which established channels does the recommender associate with this input channel" — useful for competitor mapping and audience overlap, weighted by subscriber count and recommender history. NicheBreakout answers "which small channels currently breaking out share the format fingerprint of this input channel" — useful for research and modeling, gated on channel age and first-5 performance. The two product slices are adjacent, not substitutes. The right pairing for most operators is vidIQ for audience-overlap similarity on established channels and NicheBreakout for format-fingerprint similarity on small channels currently winning.
Can I find similar small channels?
Yes, and that is the slice NicheBreakout is built around. The library is a pre-filtered cohort of channels under 45 days old at detection, with first-five-video sum views ≥ 10,000 and lifetime views per day ≥ 1,000. To find channels similar to a reference channel, identify the reference channel's format fingerprint — Shorts ratio, video length distribution, faceless vs face-on-camera, topic cluster — and browse the library or programmatic topic pages (AI story channels, Reddit story channels, history shorts channels, faceless storytelling channels, quiz channels) filtered to the matching fingerprint. The output is small channels currently breaking out inside the same format-topic intersection.
Are "similar" channels the same as "competing" channels?
No, and conflating them is a common research mistake. Similar channels share format-fingerprint or audience-overlap properties with a reference channel; competing channels are the specific channels a creator is trying to outperform inside a chosen format-topic intersection. A small breakout channel can be similar to a 2-million-subscriber reference channel — same format, same topic cluster — without being a competitor in any practical sense, because the audience scales differ by three orders of magnitude. The competitor question gets answered downstream of niche selection by the YouTube competitor analysis workflow; the similar-channel question gets answered upstream as part of research and modeling. Use the right framing for the right decision.
How accurate is similar-channel detection?
Accuracy depends on the similarity definition. Audience-overlap similarity (vidIQ, Social Blade) is accurate within the constraints of the recommender data the tools have access to, which is partial — neither has full access to YouTube's internal co-viewing graph. Topic-keyword similarity (ChannelCrawler, autocomplete-driven tools) is accurate to the keyword overlap it computes from public titles and descriptions, but misses channels whose metadata uses different language for the same format. Format-fingerprint similarity (NicheBreakout's frame) is deterministic from public Data API fields, so it is fully auditable, but it requires the researcher to read the reference channel's fingerprint first rather than typing a URL into a single-input form. Each definition is accurate within its own model; the choice of model is what determines whether the output is useful.
Is there a similar YouTube channel finder that focuses on new channels?
Most similar-channel surfaces — vidIQ Suggested, Social Blade similar, YouTube's own sidebar — weight their output by subscriber count or recommender momentum, both of which select for established channels. NicheBreakout's library is the slice of the category that pre-filters for new channels: channel age ≤ 45 days at detection, with deterministic gates on first-5 sum and view velocity. The trade-off is intent specificity: NicheBreakout will not surface a similar 2-million-subscriber reference channel because that channel does not clear the small-channel-breakout filter. If the question is "find small channels currently breaking out that are similar in format to this reference," this is the right entry point. If the question is "find any channels similar to this reference regardless of size," the broader similar-channel tools are the right entry point.
Methodology / About this analysis
NicheBreakout's research relies entirely on YouTube Data API v3 public fields: channel age, subscriber count, video count, view count, video metadata, video publish dates, video duration, and recent video performance. No private metrics (watch time, RPM, retention, audience demographics, traffic sources, audience-overlap data) appear in the live library, the Friday digest, or anywhere else on the page. The format-fingerprint similarity model discussed on this page is computed deterministically from the public fields above; the audience-overlap and recommender-graph similarity slices are not products we build — those intents are routed to the external surfaces that already serve them.
Original-research artifacts in this article: the four-model split of channel similarity in the opening section, the honest one-line read on each existing similar-channel surface, the format-similarity-beats-audience-similarity argument for new-channel research, the deterministic three-gate filter for finding format-similar small channels, and the revealed channel cards above the fold. Cluster mix reflects what we have scanned, not all of YouTube. Author: Nicholas Major (Founder, NicheBreakout · Software engineer since 2011). Article last revised 2026-06-27.
Live scan freshness:
Related research
- YouTube channel research: parent pillar covering the broader discovery-plus-inspection workflow this page sits inside.
- YouTube channel finder: sibling cluster page covering the broader channel-finder category, including ID lookup and recommendation-engine slices.
- YouTube niche finder: sister pillar covering niche-level research across faceless and face-on-camera channels.
- Faceless YouTube niches: sister pillar covering the faceless production-mode angle.
- YouTube Shorts trends: sister pillar covering the Shorts-first publishing surface.
- YouTube outlier finder: sister pillar covering the breakout-discovery framing applied to any channel type.
- Most profitable YouTube niches: companion listicle backed by examples from the live discoveries cohort.
- How to do YouTube niche research: the full process guide downstream of niche selection.
- How to find small YouTube channels: the manual-workflow version of the deterministic filter used here.
- AI story channels: programmatic topic page tracking the AI-storytelling cluster.
- Reddit story channels: programmatic topic page tracking the Reddit-narration cluster.
- History shorts channels: programmatic topic page tracking the history-shorts cluster.
- Faceless storytelling channels: programmatic topic page tracking the broader storytelling cluster.
- Quiz channels: programmatic topic page tracking the quiz/trivia cluster.
The Friday digest sends three current breakout channels every week with format fingerprints and outbound YouTube links — each one a research-worthy candidate, free, present-tense. The live library refreshes daily and surfaces channels currently inside the 30-day window. See pricing for the current tier; subscribe to the digest free.
End of cluster
Find format-similar small breakout channels today
Every channel card outbound-links to YouTube so the format-fingerprint match against a reference channel can be verified directly. The live under-30-day library is the paid workflow; the Friday digest is free.