/ Pillar · YouTube channel research
YouTube channel research: how to find the channels worth researching, then research them
YouTube channel research is two activities under one label: discovery (finding channels worth researching) and inspection (reading public data about a known channel). Most tools in this category — vidIQ, Social Blade, NoxInfluencer, ChannelCrawler — cover only the inspection layer. Inspection without discovery means you only ever research the channels you already know about, which are usually the largest channels in your niche. NicheBreakout flips it: discovery first, then inspection. Public YouTube Data API v3 metadata only. Built from thousands of channels scanned to date.
The Friday digest reveals three current breakout channels every week for free, each one a research-worthy candidate. The live 30-day window — 319 channels under 30 days old right now — is the paid workflow surface; the matured public archive opens as a second free surface in summer 2026 once the first cohort ages out of the live window.
Open the live library →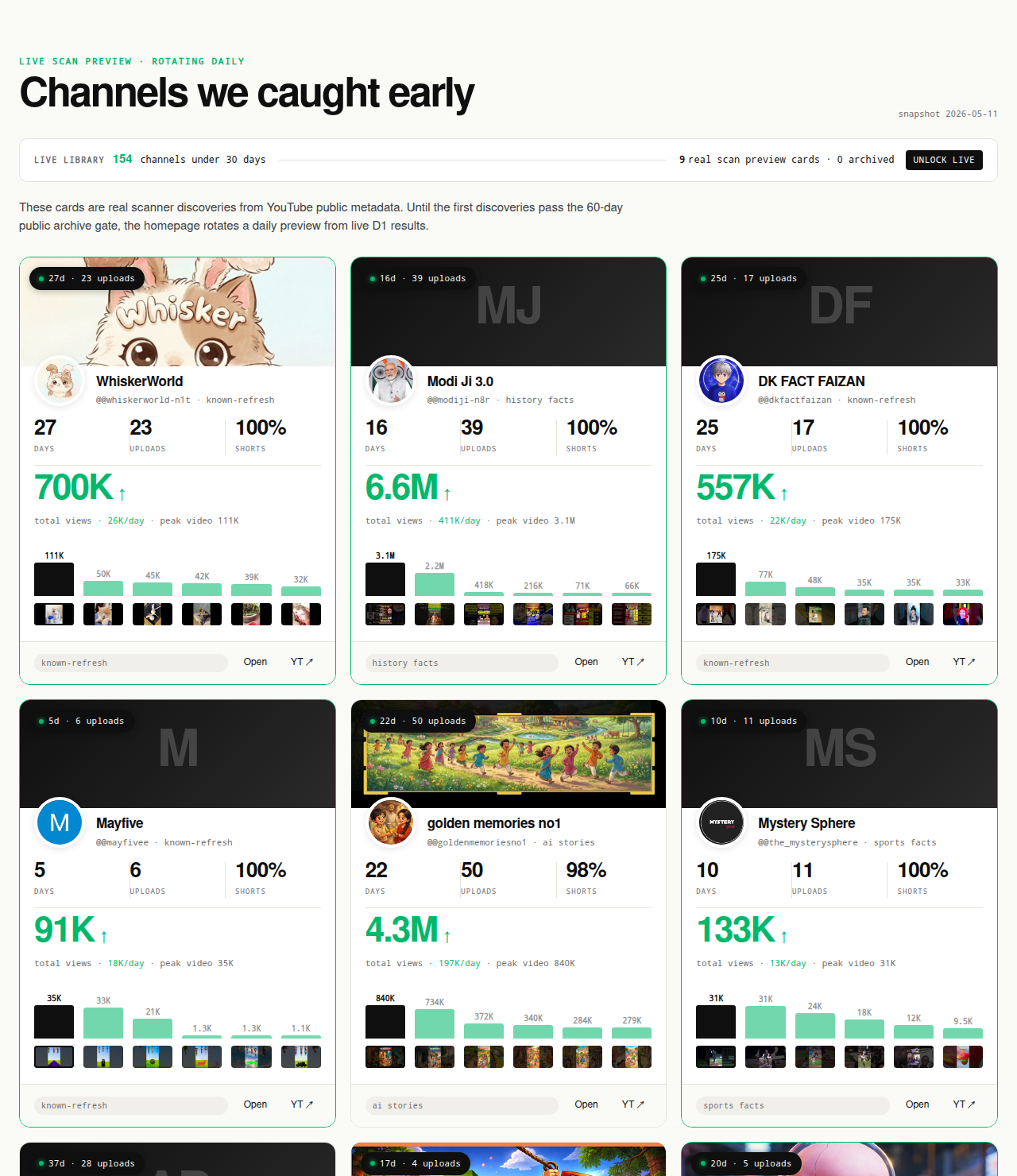
What "YouTube channel research" actually means in 2026
YouTube channel research is two activities under one label, and conflating them is why most channel-research advice underperforms. The two activities are discovery — finding channels worth researching that you don't already know about — and inspection — reading public data about a channel you already have in mind. Most tools in the category cover only the inspection layer. A creator types a known channel's URL or @handle into vidIQ, Social Blade, NoxInfluencer, or ChannelCrawler, and the tool returns public Data API fields, historical scraping, and a few proprietary estimates. The inspection layer is well-served. The discovery layer is not.
The split matters because the two activities answer different questions. Inspection answers "what is happening on this specific channel right now." Discovery answers "which channels should I be looking at in the first place." A creator who skips the discovery layer ends up researching only the channels they already know about — which are usually the largest channels in the topic, or the channels their favorite YouTube strategist talks about, or the channels they've already been watching. Those are not the channels currently breaking out at the small-channel layer where a new entrant has a meaningful path. The actually-useful research target is small channels currently winning that the researcher has not heard of, and inspection-only tools cannot surface them by definition.
The simplest practical test: write down the five channels you would research if asked right now. If all five are channels with over 500,000 subscribers, or channels that have been running for more than two years, the discovery layer is missing. The research process is being run only on the channels that have already won, not on the channels currently winning. Both are useful inputs, but only one of them tells you what is working at the format-topic intersection a new channel would actually enter.
This pillar covers both layers. The discovery sections (deterministic filters, the three-gate methodology, small-channel cohort framing) handle the upstream question. The inspection sections (the six-step per-channel routine, the inspection toolbox, what each tool is honestly good for) handle the downstream question. The order matters: discovery is upstream of inspection. Inspecting the wrong channels at high resolution is research theater. Inspecting the right channels at any resolution is research.
The inspection toolbox: what public data tells you about any channel
Inspection is the activity most "channel research" tools sell, and the activity any researcher with the YouTube Data API v3 documentation can perform without buying anything. The public fields exposed by the API are the floor — everything below is computable from those fields, and everything above (watch time, RPM, audience retention, traffic sources) lives behind the YouTube Analytics API where no third party can read it. The canonical list of channel-level public fields is in the YouTube Data API reference: "the number of subscribers that the channel has [...] is rounded down to three significant figures" (YouTube Data API: channels.list). That rounding constraint matters for any inspection that depends on small subscriber-count deltas — a channel showing 14,500 subs might actually have 14,567.
The third-party inspection tools each wrap the same public Data API fields with different presentation, different historical scraping windows, and different proprietary estimates. The honest one-line read on each:
- vidIQ — strongest for on-channel optimization (keyword research for your own videos, tag suggestions, thumbnail tests). For competitor inspection it is fine but not differentiated; the channel-research views show the same public fields any other wrapper does (vidIQ). Best used as a video-optimization companion on your own channel, not as a primary inspection tool for competitors.
- TubeBuddy — overlapping with vidIQ on the on-channel optimization side. Strong A/B testing tools for your own thumbnails and titles. Competitor-research features are present but secondary.
- Social Blade — the longest-running historical-scraping wrapper. Daily subscriber and view-count history going back years is the differentiator. The estimated earnings band is extrapolated from view counts and assumed RPM, not from any private data; treat it as decoration (Social Blade).
- NoxInfluencer — overlap with Social Blade on historical metrics. Stronger on creator-side influencer-marketing framing. Same public-data ceiling.
- ChannelCrawler — closer to the discovery layer than the inspection layer. Filterable directory of YouTube channels with subscriber-count and creation-date filters. Useful as a discovery prefilter, weaker as a per-channel inspection surface.
None of these tools have access to anything the public YouTube Data API does not expose. The differentiation between them is presentation, history depth, and the secondary features (keyword tools, A/B testing, influencer-marketing reports) layered on top of the same data floor. The right framing for a researcher choosing an inspection tool: pick the one whose presentation matches your workflow, do not pick based on claims of "deeper data" that the API does not actually expose.
Why inspection without discovery is the most common research mistake
The dominant pattern in YouTube channel research is to inspect the channels you already know about. A creator opens vidIQ, types in the URL of the largest channel in their niche, reads the public metadata, and writes down conclusions. The conclusions usually amount to "this channel is large, publishes weekly, has high view counts, and uses thumbnails with bold text." That is not research. That is a description of a channel that already won. It does not tell the researcher anything about which channels are currently winning, because the channel being inspected is downstream of two years of recommender-trained audience momentum.
The mistake compounds because the channels a creator knows about are not a random sample. They are biased toward the channels that are already large enough to surface through normal viewing, recommendation, or word-of-mouth — which selects for channels that broke out 12 to 36 months ago and have since accumulated subscriber-driven views. The channels currently breaking out at the small-channel layer are, almost by definition, channels the researcher has not heard of yet. They have fewer subscribers, less recommendation history, and have not yet been written up in YouTube-strategy listicles. Inspection-only research filters them out by accident.
The corrective is to start with discovery, then inspect. The discovery layer surfaces channels that meet a deterministic small-channel-breakout filter — channel age, first-five-video performance, view velocity — regardless of whether the researcher has heard of them. Once that filter has produced a candidate cohort, the inspection workflow runs against that cohort instead of against the researcher's existing mental list. The output of the research is a list of currently-breaking-out channels worth studying, not a description of channels that already won.
The asymmetry is the whole reason NicheBreakout exists as a separate product category from the inspection tools. vidIQ, Social Blade, and the rest of the inspection cohort do their job well; they are not broken. They are just downstream of the question the research process should actually start with. A pure-inspection workflow on the wrong cohort produces precise descriptions of irrelevant channels. A discovery-plus-inspection workflow on the right cohort produces actionable research. The cost of getting the order wrong is months of studying the wrong channels.
The deterministic framework for channel discovery
The discovery layer needs a deterministic filter that surfaces channels worth researching, not a subjective shortlist of channels someone already knows. NicheBreakout applies three hard public-metadata gates to every candidate, then ranks the survivors with a deterministic score that weights two additional signals. The full methodology is published on the methodology page; the abbreviated version below is the signal list a researcher can apply with the public YouTube Data API directly.
Channel age
detected within 45 days of channel creationFirst-5 upload views
combined views across the first five public uploads ≥ 10,000Views per day
lifetime channel views ÷ channel age ≥ 1,000Format clarity (bonus)
score weights channels with a clear Shorts-first or long-form-first ratio above mixed-format channelsEarly-traction velocity (bonus)
score boost when channel age ≤ 14 days, first-5 sum ≥ 50,000, or views/day ≥ 5,000
Each of the three hard gates isolates a different piece of the early-traction picture. Channel age ≤ 45 days filters discovery to channels where recommendation surfaces — not subscribers — are doing the audience-finding work, which is the cohort where format-fit signal is readable without confounding by subscriber inertia. First-five-video sum views ≥ 10,000 filters out channels whose first uploads landed flat; five uploads sharing 10,000 views indicates a working content vehicle rather than a single lucky upload. Lifetime views per day ≥ 1,000 is the cleanest velocity check available from public metadata alone, because watch time and impressions live behind the YouTube Analytics API and cannot be third-party-verified.
The two score bonuses sharpen ranking inside the filtered set. Format clarity rewards channels with a consistent Shorts-first or long-form-first ratio; format-mixed channels are harder to classify, harder to copy, and slower to compound on the recommender side. Early-traction velocity (channel age ≤ 14 days, first-5 sum ≥ 50,000, or views/day ≥ 5,000) pushes the freshest, fastest-moving channels to the top of the ranking inside any niche. The combination of the three gates plus the two bonuses produces a research-worthy cohort that a per-channel inspection workflow can then run against.
Average first-five-video views for every populated grade tier inside our discoveries cohort looks like this (grades with no current members are suppressed until they fill in):
- 432,083 average first-5 views
The exact score formula and grade thresholds live on the methodology page. The cross-pillar how to find small YouTube channels guide walks through how to apply these signals to channel discovery without using NicheBreakout's library.
What to do once you've found a candidate channel: the six-step inspection workflow
Once the discovery layer has produced a candidate cohort, the inspection workflow runs per-channel. The six steps below are the routine a researcher can apply with the public Data API alone, no paid tooling required. Inspection-tool wrappers (vidIQ, Social Blade) speed up the data-gathering side but do not change the routine itself; the same six questions get asked regardless of which surface answers them. The formalized version with thresholds lives in the YouTube niche validation checklist; the version below is the per-channel inspection sequence.
Step 1. Check channel age. Pull the channel's creation date from the Data API or read it off the channel's "About" tab. If the channel is older than 90 days, its current performance is downstream of recommender-trained audience momentum, and copying its current strategy is copying the steady-state behavior of an already-trained channel. Channels under 45 days old are the cohort where format-fit signal is cleanest; channels between 45 and 90 days old are useful as transitional examples.
Step 2. Read first-five-video performance. Pull the channel's first five public uploads in publish order and read each video's view count. A working channel typically has a combined first-5 sum above 10,000 views, with no single video dominating the total. A channel with one viral 50,000-view first upload and four uploads under 1,000 views each is a single-viral-video case, not a working format. The first-five-video distribution tells you whether the format itself is being lifted by the recommender.
Step 3. Inspect format consistency. Scroll the channel's uploads tab and read off the format fingerprint: video length distribution, vertical vs horizontal, Shorts ratio, faceless vs face-on-camera, single-host vs multi-host. A working channel typically locks one format in the first 10-20 uploads and stays there. A format-mixed channel (three Shorts, one long-form, one livestream) teaches the recommender contradicting audience profiles and the early-traction signal flatlines.
Step 4. Sample three recent thumbnails. Thumbnails are not exposed as a queryable field in the Data API but they are the variable with the largest measurable effect on click-through. Pull three thumbnails from the channel's recent uploads and read off the visual template: dominant color, text presence, face presence, composition. Channels currently breaking out usually have a consistent thumbnail style across their first 10-20 uploads. Thumbnails that drift between styles tell you the channel is still iterating; thumbnails locked into a template tell you the channel has settled on a format-fit hypothesis.
Step 5. Check upload cadence. Read off the channel's publish dates from the first 10 uploads. A working channel typically publishes inside a tight cadence (daily, every other day, twice a week) in the first 30 days. Channels that publish three uploads in week one and then nothing for two weeks teach the recommender an unstable channel profile and the format-fit signal cools. Cadence is the variable inspection tools rarely surface as a primary signal, but it is one of the strongest format-fit predictors in our scan data.
Step 6. Verify the channel doesn't post-and-pivot. The hardest pattern to catch from a single inspection pass is the channel that publishes ten uploads in one format, deletes them, and re-launches in a different format under the same channel ID. Read off the channel's earliest public upload date versus the channel creation date. If there is a multi-week gap, or if the upload count is conspicuously round (exactly 10, exactly 20), the channel may be a re-launch and the format-fit signal is contaminated. Channel re-launches are not necessarily disqualifying — they often produce working channels — but they need to be flagged so the researcher does not mistake a re-launched channel's first-month performance for a fresh-channel breakout.
Competitor research vs. niche research: two different upstream questions
"Channel research" and "niche research" are often used interchangeably, but they answer different upstream questions and require different inputs. Competitor research is the activity of studying existing players inside a niche the researcher has already chosen. The output is a list of what specific competitors are doing — format, cadence, thumbnail style, topic mix — and the input is the niche itself plus a candidate competitor cohort. Niche research is the activity of deciding whether the niche itself is worth choosing. The output is a verdict on whether a niche is producing small-channel breakouts; the input is breakout density at the format-topic intersection. The two questions are upstream and downstream of each other, and skipping the niche-research step puts a researcher into competitor research inside a niche that may or may not be working.
The product categories split along the same line. vidIQ and TubeBuddy lean toward the competitor-research side: their primary surfaces are built around the channel and the keywords a competitor is using. NicheBreakout focuses on the niche-research side: the primary surface is the cohort of small channels currently breaking out, which is what the niche-research verdict reads from. Social Blade, NoxInfluencer, and ChannelCrawler sit somewhere in between, with stronger competitor-research framing in their per-channel views and weaker niche-research framing in their directories. None of these tools is the wrong product for one of the two activities; each is the wrong product for the other.
The practical sequence is niche research first, competitor research second. A researcher who has not yet picked a format-topic intersection runs niche research across multiple candidates, picks the intersection where small channels are currently breaking out, and then runs competitor research against the specific channels operating at that intersection. A researcher who has already committed to a format-topic intersection skips ahead to competitor research and uses the inspection toolbox accordingly. Reversing the order — running competitor research first to "pick a niche" — produces niche selection by inspection of channels that already won, which is the discovery-skipping mistake the previous section described.
NicheBreakout's YouTube niche finder pillar is the niche-research entry point. The YouTube niche validation checklist formalizes the niche-research step into a workflow. Competitor research downstream of that selection runs against the channels surfaced by the discovery layer, then through the six-step inspection routine above.
What we deliberately don't claim about competitor channels
NicheBreakout does not claim access to private YouTube Analytics API metrics for any channel a researcher does not own. Watch time, audience retention, RPM, average view duration, traffic source breakdown, audience demographics, click-through rate on impressions, and subscriber geography all live behind authenticated endpoints that Google restricts to channel owners and authenticated content partners (YouTube Data API: channels.list; the Analytics API documentation describes the authentication boundary in more detail). None of those metrics ship in the live library, the Friday digest, the future matured public archive, or anywhere else on the page. Any third party selling "competitor watch time," "competitor RPM," "competitor traffic sources," or "competitor retention" for channels they do not own is either inferring from non-API sources, extrapolating from public data with assumptions the researcher cannot audit, or fabricating the number.
What is publishable from public Data API v3 fields for any channel: channel age, subscriber count (rounded to three significant figures, or hidden if the channel has hidden subscribers), total view count, video count, upload playlist ID, channel description, channel banner, channel thumbnail, country (if set), custom URL (if set), and per-video metadata including title, description, publish date, duration, view count, like count, comment count, and tags. From those fields a researcher can compute everything the inspection workflow above relies on. From those fields a researcher cannot compute watch time, RPM, retention, traffic sources, or revenue, because the inputs to those metrics are private.
The boundary is structural, not defensive. The inspection workflow does not need private metrics to produce useful research — it needs the right cohort of channels and the discipline to ask the same six questions of each one. The channels that surface through the discovery layer are channels a researcher can audit by clicking through to YouTube and reading the public metadata directly. Every claim on this pillar is defensible from one of the public Data API fields above, and every channel in the library carries an outbound link to YouTube so the public metadata is verifiable in one click. The "verifiable on YouTube" property is non-negotiable; if a claim cannot survive that audit, it does not go on the page.
Common channel-research mistakes
Six mistakes recur in YouTube channel research, and each of them is correctable with a discipline change rather than a tool change. Researching only the biggest channels in a niche. The largest channels in a topic are downstream of years of recommender-trained audience momentum; their current strategy is the steady-state behavior of an already-trained channel, not the format-fit hypothesis a new entrant should copy. The corrective is to deliberately filter for channels under 45 days old at the format-topic intersection the researcher is considering.
Treating subscriber count as the primary signal. Subscriber count lags early traction by months, can be rounded down to three significant figures by the Data API, and can be hidden entirely by the channel owner. A channel with 800 subscribers and a first-5 sum of 200,000 views is breaking out; a channel with 80,000 subscribers and 500 views per day is in decline. Subscriber count alone does not distinguish them. View velocity (lifetime views ÷ channel age) and first-5 sum are stronger signals.
Copying the topic without copying the format. A working YouTube channel is a format-topic intersection. A researcher who copies the topic list of a viral history-shorts channel but films it as a face-on-camera long-form documentary is running a different channel from the recommender's perspective and the early-traction signal flatlines. The corrective is to read the format off the breakout channel — production mode, video length, publish cadence, visual style — and run the researcher's own topics inside that format.
Ignoring channel age. New researchers study channels with 500,000 subscribers and copy their current strategy, missing that the mature channel's current strategy is downstream of two years of recommender-trained audience momentum. The corrective is to study channels under 90 days old inside the same niche — the channels currently winning, not the channels that won. The YouTube niche validation checklist operationalizes this into a workflow.
Conflating one-off viral videos with channel-level breakouts. A single video with 1,000,000 views on a channel whose other uploads sit under 1,000 views each is a viral fluke, not a working channel. Channel-level research needs first-5 distribution data, not single-video peak counts. The corrective is to read first-five-video performance in publish order, not to fixate on the channel's highest-view upload.
Trusting "best YouTube channels in X" listicles. Most listicles are recycled annually with dates swapped; a 2026 list often re-uses the same channels named in a 2023 list. The channels named are usually channels that have been large for years, which is the opposite of the discovery-layer target. The corrective is to ignore listicles for discovery and rely on deterministic public-metadata filters instead — or to use listicles only as a starting point for niche selection, never as the source of channels to research.
Each of these mistakes shares a root cause: the researcher is treating channel research as inspection of channels they already know about, instead of discovery-plus-inspection of channels currently winning that they have not heard of yet. The discipline change is to add the discovery layer upstream of the inspection layer, then run the inspection routine on the right cohort.
The cluster currently surfacing the most research-worthy channels in our scans
The discovery-layer output is most useful when it points at specific clusters where the small-channel-breakout signal is firing right now, not at a generic "all channels in our index" list. Across the 319 channels currently in our live 30-day window (a subset of the broader thousands of-channel scan), the densest niche clusters currently meeting our sample-size threshold are:
- 38.4 hotness score
- 36.8 hotness score
- 35.9 hotness score
This is what we've observed in our scans, not a market-wide claim, and it shifts week over week as new format clusters surface and older ones saturate. Read it as a current snapshot. The Shorts-first vs long-form split inside those top clusters looks like this in our dataset:
The clusters surfacing the most research-worthy channels are usually faceless or Shorts-first formats — AI storytelling, history shorts, Reddit narration, quiz/trivia, faceless storytelling — because those formats have the lowest production cost per upload, which lets a single operator publish enough times inside the 45-day early-traction window to produce readable signal. Face-on-camera long-form channels also break out, but they cluster less densely and are spread across more topic categories.
Five recurring clusters have dedicated programmatic topic pages where each one's currently-breaking-out channels are indexed with the same outbound-link verification as the main library:
- AI story channels: TTS narration plus AI imagery, recurring story templates, Shorts-first publishing.
- Reddit story channels: TTS reading r/AmITheAsshole, r/ProRevenge, r/MaliciousCompliance threads with stock visuals or simple character overlay.
- History shorts channels: fact-stacking with cinematic visuals, vertical and horizontal variants.
- Faceless storytelling channels: broader narrative format spanning fiction and non-fiction.
- Quiz channels: interactive Q&A format, often Shorts-first with text overlays.
If channel research is the entry-point activity, the programmatic pages above are the natural next click: each one is a pre-filtered candidate cohort for the inspection workflow to run against. The faceless YouTube niches and YouTube Shorts trends sister pillars cover the production-mode and surface-mode angles for the operators picking which cluster to research first.
FAQ
What's the best YouTube channel research tool?
It depends on whether you need discovery or inspection. For inspection — reading public data about a channel you already know — Social Blade and vidIQ are the workhorses; both wrap the public YouTube Data API and add their own estimates. For discovery — finding small channels currently breaking out that you haven't heard of yet — NicheBreakout, ChannelCrawler, and TubeLab each take different angles. Most operators end up using one tool from each layer. A single tool that does both well does not currently exist, and any product claiming to cover both usually does one well and the other as a thin afterthought.
How do I research my YouTube competitors?
Start by deciding who your competitors actually are. The competitors that matter for a new or growing channel are small channels currently breaking out in your format-topic intersection, not the largest channels in the topic. Pull a list of channels under 45 days old at that intersection (NicheBreakout's library, ChannelCrawler's filters, or a manual search filtered by upload date will all surface candidates), then run each through the six-step inspection routine described in the per-channel workflow section above: channel age, first-5 performance, format consistency, thumbnail style, upload cadence, and post-and-pivot check.
Can I see another YouTube channel's analytics?
No. The YouTube Analytics API is owner-only and authenticated; watch time, audience retention, traffic source breakdown, average view duration, RPM, and revenue are not exposed to third parties for any channel you do not own. What is publicly readable through the YouTube Data API: channel age, subscriber count (rounded to three significant figures), total view count, video count, individual video view counts, video metadata, and video publish dates. Any tool that claims to show another channel's watch time, RPM, or traffic-source breakdown is either inferring from non-API data or fabricating the number.
Is Social Blade accurate?
Mostly, for the metrics it reports directly. Social Blade is a wrapper over the same public YouTube Data API fields any third party can read, plus historical scraping for the trend lines. The numbers it shows for current subscribers, total views, and video count are accurate to the rounding the API itself applies (subscribers are rounded down to three significant figures). The estimated earnings ranges are not accurate in the literal sense; they are extrapolations from public view counts using assumed RPM ranges, and per-channel RPM lives behind the YouTube Analytics API where no third party can read it. Treat the metrics as accurate; treat the earnings band as decoration.
How do I find small YouTube channels to research?
Filter by channel age and upload count, then sort by view velocity. The deterministic version is the three-gate filter we apply in the live library: channel age ≤ 45 days, first-five-video sum views ≥ 10,000, lifetime views per day ≥ 1,000. ChannelCrawler exposes filters for channel age and subscriber count; NicheBreakout publishes the filtered cohort with format labels; TubeLab covers a similar discovery angle. The mistake to avoid is starting from a subscriber-count threshold ("channels under 10,000 subscribers") — subscriber count lags behind early traction by months and surfaces stale channels next to currently-breaking-out ones.
Can I copy a successful YouTube channel?
You can copy the format; copying the topic alone is the most common research mistake. A working YouTube channel is a format-topic intersection — for example, vertical TTS history shorts with cinematic visuals and captions on every line. The format is the replicable part; the specific topic the channel is currently running inside that format will saturate in weeks while the format keeps producing breakouts for months. Channels that copy a viral channel's topic list but film it in a different format end up with a different channel from the recommender's perspective and the early-traction signal flatlines. Read the format off the breakout channel and run your own topics inside it.
What public data is available for any YouTube channel?
Through the YouTube Data API v3: channel ID, channel title, channel description, channel creation date, country, custom URL, subscriber count (rounded to three significant figures, hidden if the channel has hidden it), total view count, video count, upload playlist ID, channel banner, channel thumbnail, and per-video metadata (title, description, publish date, duration, view count, like count, comment count, tags). Not available without authentication for a channel you don't own: watch time, audience retention, traffic sources, RPM, revenue, subscriber demographics, geographic breakdown, click-through rate on impressions, and average view duration. Everything in the first list is fair game for research; everything in the second list is private.
How is NicheBreakout different from vidIQ or Social Blade?
vidIQ and Social Blade are inspection tools — you give them a channel you already know about, they return public metadata plus their own estimates. NicheBreakout is a discovery tool — it surfaces small channels currently breaking out that you don't already know about, then leaves the inspection step to whichever tool you prefer. The product categories are adjacent, not substitutes. The right pairing for most operators is a discovery tool (NicheBreakout, ChannelCrawler, or TubeLab) to find candidates and an inspection tool (vidIQ, Social Blade, or NoxInfluencer) to dig into specific channels once you have them.
Methodology / About this analysis
NicheBreakout's research relies entirely on YouTube Data API v3 public fields: channel age, subscriber count, video count, view count, video metadata, video publish dates, video duration, and recent video performance. No private metrics (watch time, RPM, retention, audience demographics, traffic sources) appear in the live library, the Friday digest, or anywhere else on the page. The discovery-layer cohort discussed on this pillar is derived from the same scan that powers the main live library; the inspection-workflow steps are the routine a researcher can apply with the same public Data API the third-party inspection tools wrap.
Original-research artifacts in this article: the discovery-vs-inspection two-layer framing in the opening section, the honest one-line read on the major inspection tools, the deterministic three-gate filter for discovery, the six-step per-channel inspection workflow, the competitor-vs-niche-research split, the live niche-cluster snapshot, and the revealed channel cards above the fold. Cluster mix reflects what we've scanned, not all of YouTube. Author: Nicholas Major (Founder, NicheBreakout · Software engineer since 2011). Article last revised 2026-06-27.
Live scan freshness:
Related research
- YouTube niche finder: sister pillar covering niche research across faceless and face-on-camera channels.
- Faceless YouTube niches: sister pillar covering the faceless production-mode angle.
- YouTube Shorts trends: sister pillar covering the Shorts-first publishing surface.
- YouTube outlier finder: sister pillar covering the breakout-discovery framing applied to any channel type.
- Most profitable YouTube niches: companion listicle backed by examples from the live discoveries cohort.
- How to do YouTube niche research: the full process guide downstream of niche selection.
- YouTube niche validation checklist: the deterministic checklist version of the methodology.
- Why we are not a keyword research tool: positioning piece on the adjacent category we don't compete in.
- AI story channels: programmatic topic page tracking the AI-storytelling cluster.
- Reddit story channels: programmatic topic page tracking the Reddit-narration cluster.
- History shorts channels: programmatic topic page tracking the history-shorts cluster.
- Faceless storytelling channels: programmatic topic page tracking the broader storytelling cluster.
- Quiz channels: programmatic topic page tracking the quiz/trivia cluster.
The Friday digest sends three current breakout channels every week with format fingerprints and outbound YouTube links — each one a research-worthy candidate, free, present-tense. The live library refreshes daily and surfaces channels currently inside the 30-day window. See pricing for the current tier; subscribe to the digest free.
End of pillar
Find channels worth researching today
Every channel card outbound-links to YouTube so the inspection step starts from public Data API fields directly. The live under-30-day library is the paid workflow; the Friday digest is free.